 Image credit: Alessio Quercia
Image credit: Alessio Quercia
Abstract
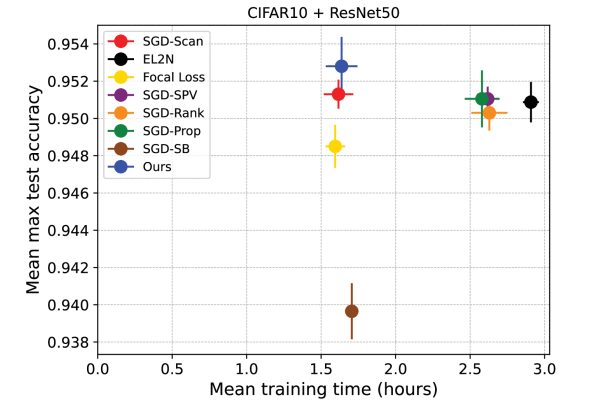
In deep learning, using larger training datasets usually leads to more accurate models. However, simply adding more but redundant data may be inefficient, as some training samples may be more informative than others. We propose to bias SGD (Stochastic Gradient Descent) towards samples that are found to be more important after a few training epochs, by sampling them more often for the rest of training.In contrast to state-of-the-art, our approach requires less computational overhead to estimate sample importance, as it computes estimates once during training using the prediction probabilities, and does not require that training be restarted.In the experimental evaluation, we see that our learning technique trains faster than state-of-the-art and can achieve higher test accuracy, especially when datasets are not well balanced. Lastly, results suggest that our approach has intrinsic balancing properties. Code is available at https://github.com/AlessioQuercia/sgd_biased.
Alessio Quercia
CS PhD Candidate @ RWTH Aachen University & FZJ | ex IBM Research Zurich, WSense
Alessio is a PhD Student in Computer Science at RWTH Aachen and at the Machine Learning and Data Analytics Institute in Forschungszentrum Jülich. He is currently focusing on Data Efficient Learning, Multi-Task Learning, Transfer Learning and Parameter-Efficient Fine-Tuning.